Convert Depth Image to Point Cloud
This page provides instructions and snippets of converting depth image to point cloud.
How to use point cloud or RGB/RGBD image as input
We often train RL with visual input in Isaac Gym and have tried it in Bi-dexhands. But the problem is that the parallelism of Isaac Gym's cameras is not very good. It can only obtain images one by one env serially, which will greatly slow down the running speed. At the same time, the training of the dexterous hand is very difficult and greatly depends on the high sampling efficiency, so we do not use the input of other modalities. But this is undoubtedly very important, so we provide an example for other modal (point cloud) inputs for future exploration or development, see here. Below is the a brief introduction.
A brief introduction to the example
First, we need to set the camera properties:
self.camera_props = gymapi.CameraProperties()
self.camera_props.width = 256
self.camera_props.height = 256
self.camera_props.enable_tensors = True
self.env_origin = torch.zeros((self.num_envs, 3), device=self.device, dtype=torch.float)
self.pointCloudDownsampleNum = 768
self.camera_u = torch.arange(0, self.camera_props.width, device=self.device)
self.camera_v = torch.arange(0, self.camera_props.height, device=self.device)
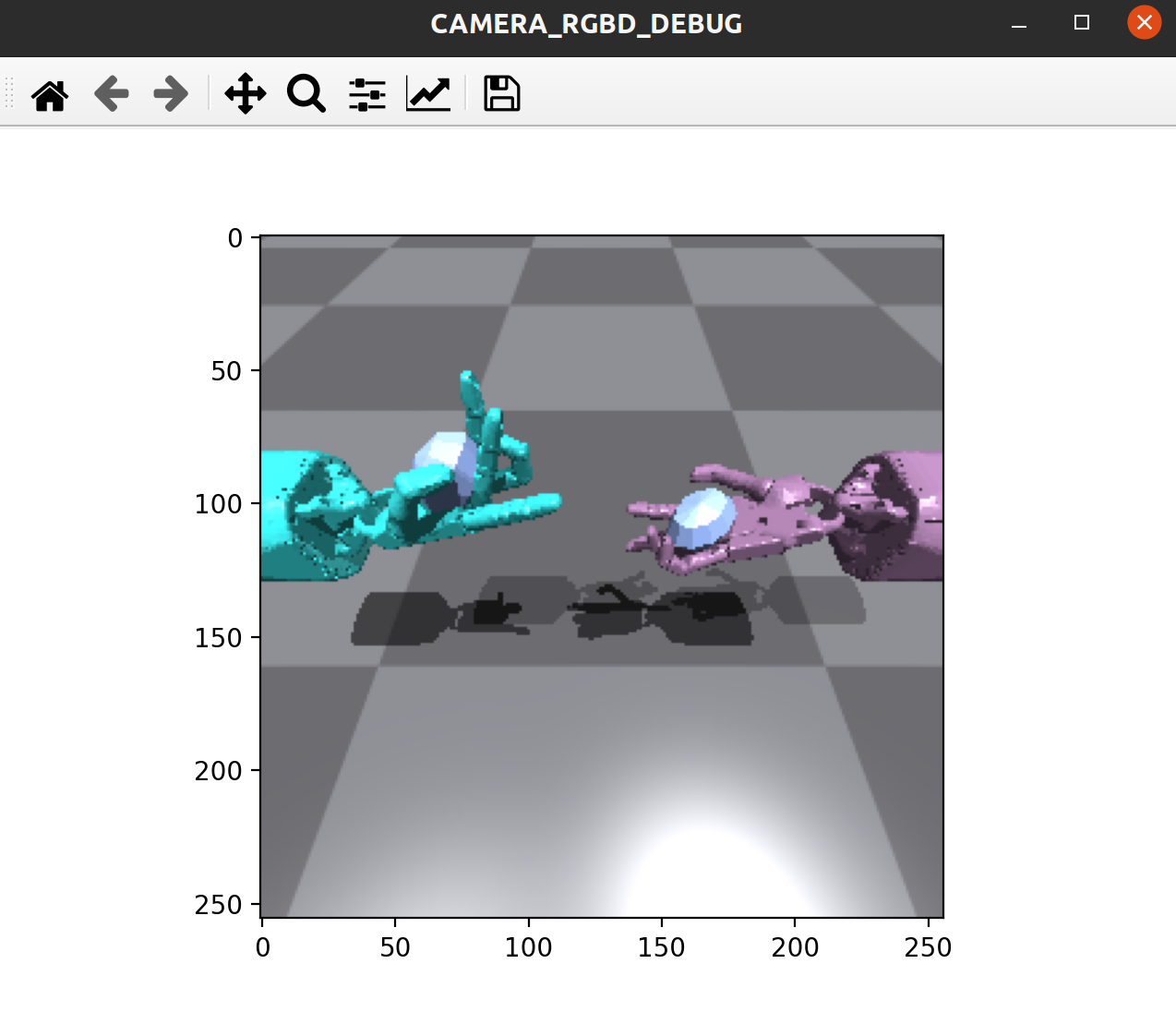
We adjust extrinsic and resolutions with camera image visualization to suit our task. Here is an example of ShadowHandOver:
self.camera_rgba_debug_fig = plt.figure("CAMERA_RGBD_DEBUG")
camera_rgba_image = self.camera_visulization(is_depth_image=False)
plt.imshow(camera_rgba_image)
plt.pause(1e-9)
Next, we create the camera and register the relevant tensor:
camera_handle = self.gym.create_camera_sensor(env_ptr, self.camera_props)
self.gym.set_camera_location(camera_handle, env_ptr, gymapi.Vec3(0.25, -0.5, 0.75), gymapi.Vec3(-0.24, -0.5, 0))
camera_tensor = self.gym.get_camera_image_gpu_tensor(self.sim, env_ptr, camera_handle, gymapi.IMAGE_DEPTH)
torch_cam_tensor = gymtorch.wrap_tensor(camera_tensor)
Image visualization:
For intrinsic, Some advanced uses such as deprojecting depth images to 3D point clouds require complete knowledge of the projection terms used to create the output images. To aid in this, Isaac Gym provides access to the projection and view matrix used to render a camera's view:
cam_vinv = torch.inverse((torch.tensor(self.gym.get_camera_view_matrix(self.sim, env_ptr, camera_handle)))).to(self.device)
cam_proj = torch.tensor(self.gym.get_camera_proj_matrix(self.sim, env_ptr, camera_handle), device=self.device)
Finally, the depth image is obtained and converted into a point cloud, which is down-sampled and placed in the observation buffer for processing by the algorithm:
points = depth_image_to_point_cloud_GPU(self.camera_tensors[i], self.camera_view_matrixs[i], self.camera_proj_matrixs[i], self.camera_u2, self.camera_v2, self.camera_props.width, self.camera_props.height, 10, self.device)
selected_points = self.sample_points(points, sample_num=self.pointCloudDownsampleNum, sample_mathed='random')
@torch.jit.script
def depth_image_to_point_cloud_GPU(camera_tensor, camera_view_matrix_inv, camera_proj_matrix, u, v, width:float, height:float, depth_bar:float, device:torch.device):
depth_buffer = camera_tensor.to(device)
vinv = camera_view_matrix_inv
proj = camera_proj_matrix
fu = 2/proj[0, 0]
fv = 2/proj[1, 1]
centerU = width/2
centerV = height/2
Z = depth_buffer
X = -(u-centerU)/width * Z * fu
Y = (v-centerV)/height * Z * fv
Z = Z.view(-1)
valid = Z > -depth_bar
X = X.view(-1)
Y = Y.view(-1)
position = torch.vstack((X, Y, Z, torch.ones(len(X), device=device)))[:, valid]
position = position.permute(1, 0)
position = position@vinv
points = position[:, 0:3]
return point
def rand_row(self, tensor, dim_needed):
row_total = tensor.shape[0]
return tensor[torch.randint(low=0, high=row_total, size=(dim_needed,)),:]
def sample_points(self, points, sample_num=1000, sample_mathed='furthest'):
eff_points = points[points[:, 2]>0.04]
if eff_points.shape[0] < sample_num :
eff_points = points
if sample_mathed == 'random':
sampled_points = self.rand_row(eff_points, sample_num)
elif sample_mathed == 'furthest':
sampled_points_id = pointnet2_utils.furthest_point_sample(eff_points.reshape(1, *eff_points.shape), sample_num)
sampled_points = eff_points.index_select(0, sampled_points_id[0].long())
return sampled_points
Down-sampled point cloud visualization:
